예제 파일을 보겠습니다.
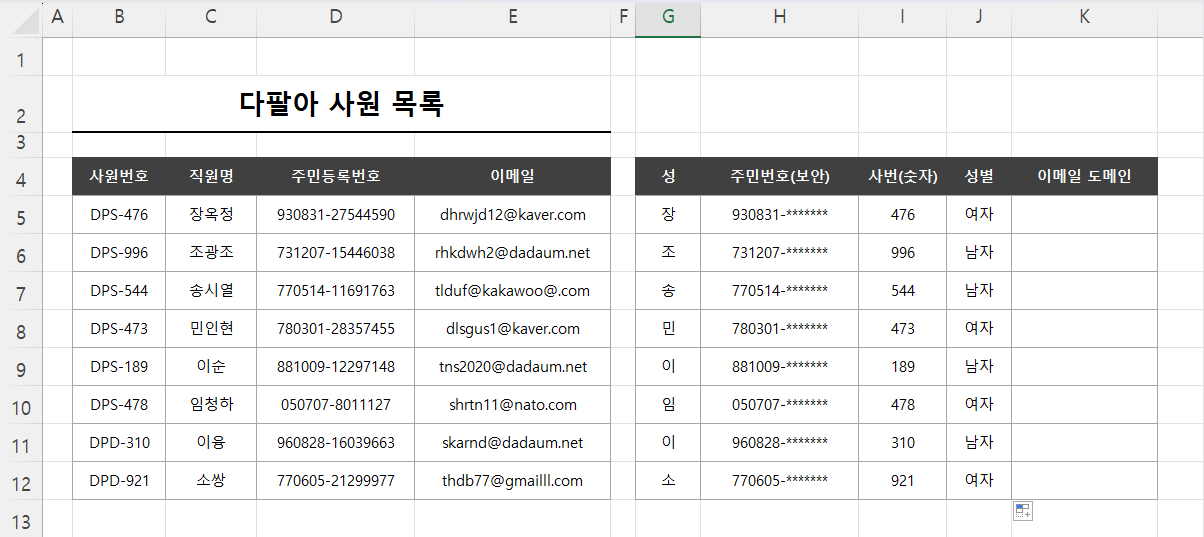
예제 파일에서 "이메일 도메인" 항목은 원본 "이메일" 항목 데이터에서 @ 다음 문자들을 반환해야 합니다.
물론 원본 데이터가 변경될 일이 없어 함수를 사용하지 않을 것이라면, 빠른 채우기가 가장 좋은 방법입니다. 텍스트 나누기를 통해서도 할 수 있죠. 두 가지 방법을 모르신다면 아래 강좌를 참고해 주시고요.
지금에 경우는 MID 또는 RIGHT 함수를 사용해야겠네요. 그런데 문제가 있죠. MID 함수를 사용하려고 보니 @ 다음 문자의 위치를 특정할 수 없습니다. 그리고 @ 다음 몇 개의 문자를 가져와야 할지도 특정할 수 없습니다. RIGHT 함수 역시 뒤 문자 몇 개를 가져와야 할지 특정할 수 없습니다. 그렇다고 데이터 한 개씩 사용할 순 없습니다. 너무 많은 작업이 되겠죠.
문제를 확인했으니, 해결 방법을 알아보겠습니다. "@" 위치와 "@" 다음 문자 개수를 특정할 수 없다는 것 때문에 생긴 문제죠. 하지만 특정할 수 있다면,
그렇다면 모든 것이 해결되겠죠. 이번 강좌는 특정 문자의 위치(숫자)를 알아내는 함수 FIND와 SEARCH 함수를 알아보고 이하 문자 개수를 알아내기 위한 LEN 함수에 대해서도 알아보겠습니다.
FIND특정 문자열에서(within_text)에서 찾고자하는 문자(find_text)를 찾아 처음 찾아진 위치(숫자)를 반환
FIND(find_text, within_text, [start_num])| find_text | 찾고자하는 문자. 대소문자를 구분하고 와일드 카드(* ? ~)는 사용 안됨 |
| within_text | 찾고자하는 문자가 포함된 특정 문자열 |
| start_num | [선택] within_text에서 검색을 시작할 문자 위치(숫자), 생략시 첫 문자(1)부터 검색 |
SEARCH특정 문자열에서(within_text)에서 찾고자하는 문자(find_text)를 찾아 처음 찾아진 위치(숫자)를 반환
SEARCH(find_text, within_text, [start_num])| find_text | 찾고자하는 문자. 대소문자를 구분하지 않고 와일드 카드(* ? ~)도 사용 가능 |
| within_text | 찾고자하는 문자가 포함된 특정 문자열 |
| start_num | [선택] within_text에서 검색을 시작할 문자 위치(숫자), 생략시 첫 문자(1)부터 검색 |
FIND, SEARCH 함수는 위와 같이 정리됩니다. 두 함수는 기능도, 인수도 모두 같습니다. 찾고자 하는 문자(find_text)의 영문 대소문자를 구분할 것인지, 와일드 카드를 사용할 것인지에 따라 FIND냐 SEARCH냐를 선택하시면 됩니다. FIND 함수는 엄격하고, SEARCH 함수는 유연하다 정도로 기억하면 되겠네요.
와일드 카드는 필터 편에서 알아본바 있습니다. 잘 모르시는 분들은 아래 강좌를 참고해 주세요.
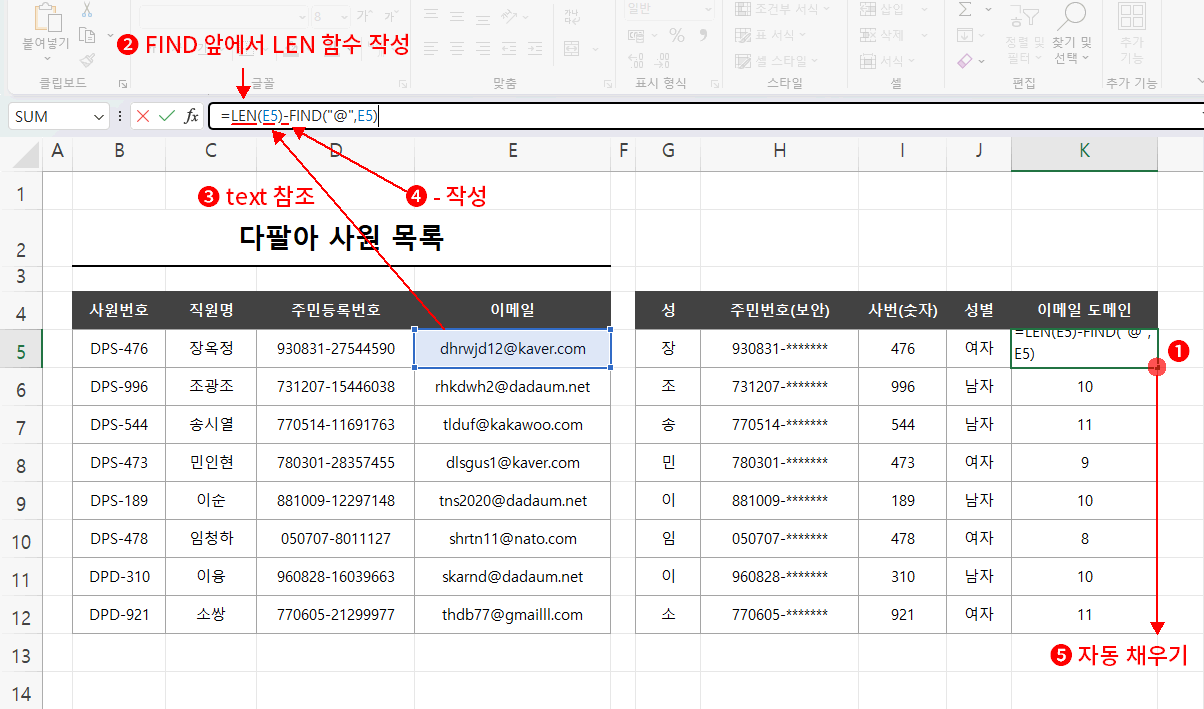
일단 원본 이메일에서 @의 위치를 찾아보겠습니다. 지금은 FIND와 SEARCH 중 아무거나 사용해도 되겠네요. FIND로 진행하겠습니다.
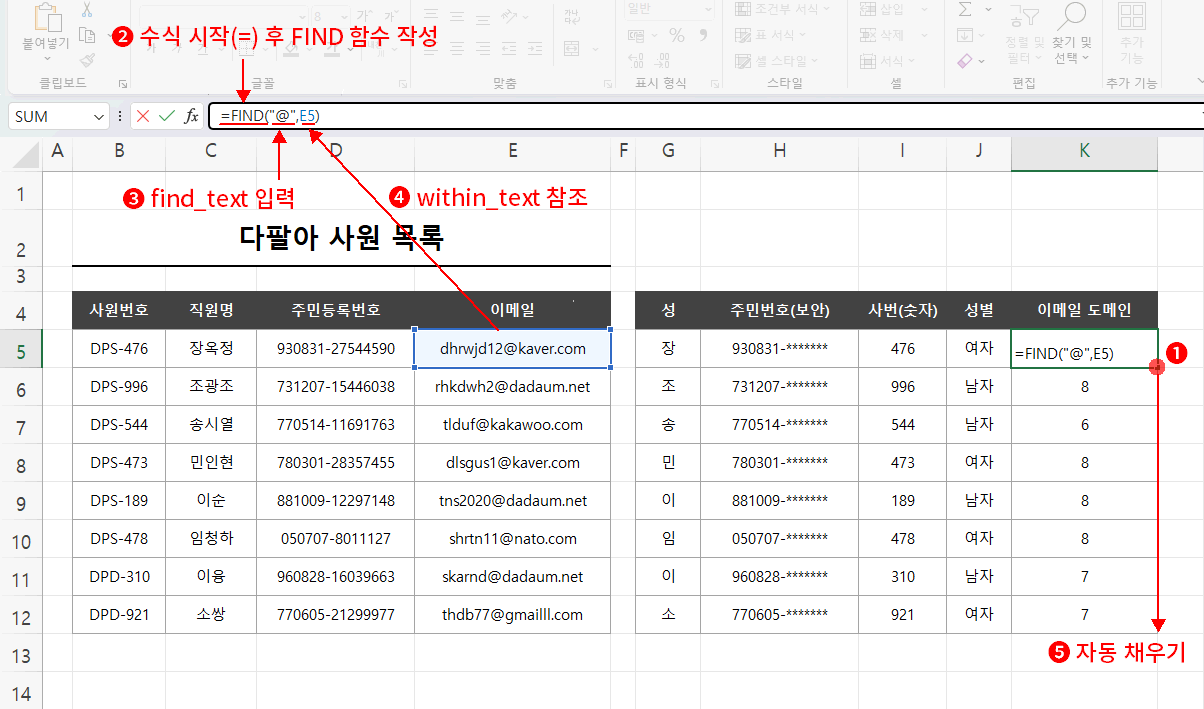
- 작성할 셀(K5)을 클릭하여 선택합니다.
- 수식 입력줄에서 수식을 시작하고 함수명을 작성합니다. => =FIND(
- 첫 번째 인수 힌트(find_text)를 확인하고 "@"를 입력합니다. => =FIND("@"
수식에서 문자는 반드시 큰따옴표로 감싸야 한다는 것 주의해 주세요. - 쉼표로 구분, 두 번째 인수 힌트(within_text)를 확인하고 가져올 데이터를 참조하고 엔터로 K5셀을 완성합니다. => =FIND("@",E5)
- 다시 완성된 K5셀을 클릭하고 나머지는 자동 채우기(우측 하단에서 클릭 드래그)로 완성합니다.
결과, @의 위치가 앞에서부터 글자 순서로 반환됩니다.
하지만 여전히 몇 개의 글자를 가져와야 하는지는 알 수 없습니다. 이걸 알기 위해서 하나의 함수를 더 알아야 합니다. LEN 함수입니다.
LENtext 문자열의 전체 문자 수를 반환합니다.
LEN(text)| text | 문자 수를 확인하려는 대상 문자열. 공백도 문자로 계산됨 |
함수 정리는 위와 같습니다. LEN은 LENGTH의 약자로 길이를 의미하며 인수를 하나만 갖는 아주 단순한 함수입니다.
전체 문자 수를 알 수 있고 "@"의 위치를 알 수 있으니, "@" 다음 문자 수는, 전체 문자 수에서 "@"까지의 문자 수를 빼주면 되겠죠. (전체 문자 수 - @ 위치)
- K5셀을 클릭하여 다시 선택합니다. => =FIND("@",E5)
- 수식 입력줄에서 FIND 함수 앞에 LEN 함수명을 추가 작성합니다. => =LEN(FIND("@",E5)
- LEN 함수의 인수 힌트(text)를 확인하고 가져올 값을 참조한 후 괄호를 닫아 LEN 함수를 완성합니다. => =LEN(E5)FIND("@",E5)
- 작성된 LEN 함수 뒤에 -(빼기)를 입력하고 엔터를 눌러 K5셀을 완성합니다. => =LEN(E5)-FIND("@",E5)
- 나머지 데이터 확인을 위해 다시 완성된 K5셀을 클릭하고 자동 채우기(우측 하단에서 클릭 드래그)를 진행합니다.
결과, @ 다음 문자열의 개수가 반환되었습니다.
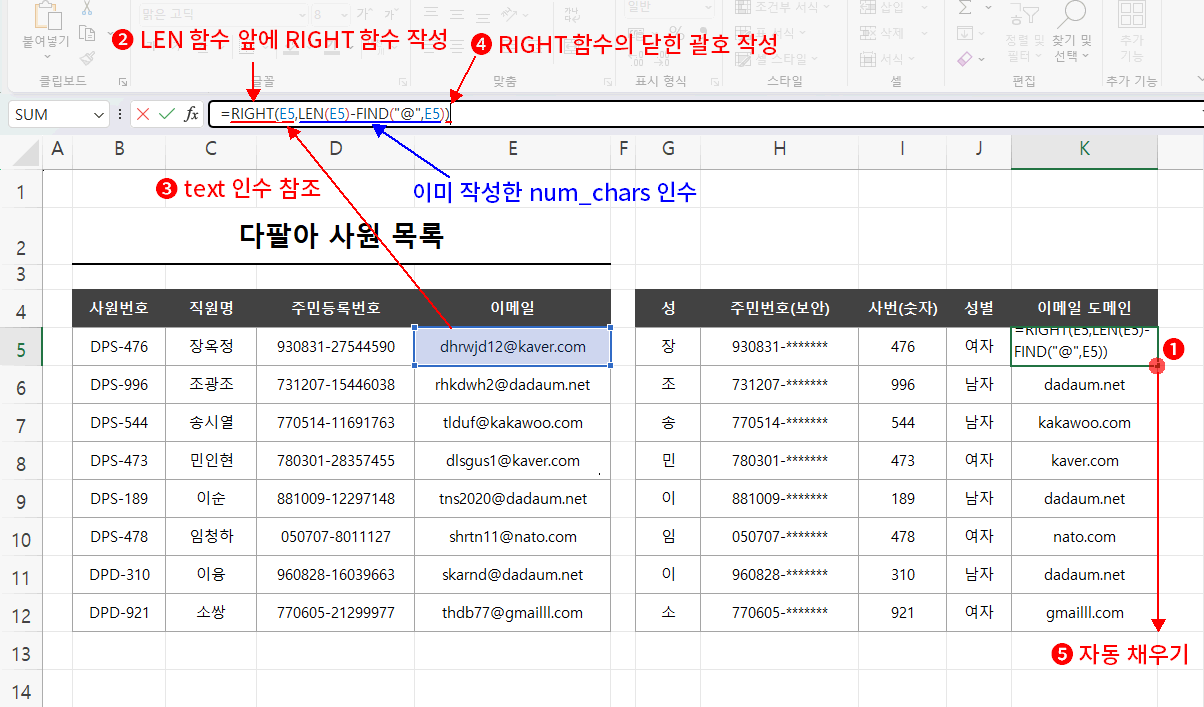
이제 남은 것은 실제 추출할 함수, MID나 RIGHT 중 하나를 사용하면 끝입니다. 간단하게 RIGHT 함수를 사용하겠습니다.
- K5셀을 클릭하여 다시 선택합니다. => =LEN(E6)-FIND("@",E6)
- 수식 입력줄에서 LEN 함수 앞에 RIGHT 함수명을 추가 작성합니다. => =RIGHT(LEN(E6)-FIND("@",E6)
- RIGHT 함수의 인수 힌트(text)를 확인하고 가져올 값을 참조한 후 쉼표를 입력합니다. => =RIGHT(E6,LEN(E6)-FIND("@",E6)
RIGHT 함수의 두 번째 인수 num_chars는 이미 작성한 수식입니다. - RIGHT 함수를 완성하기 위해 수식 마지막에 닫힌 괄호를 입력하고 엔터를 누릅니다. => =RIGHT(E6,LEN(E6)-FIND("@",E6))
함수 안에 함수를 중첩 사용할 경우 그냥 엔터는 에러가 발생한다고 했습니다. 반드시 닫힌 괄호를 작성하고 엔터를 눌러 주세요. - 마지막으로 다시 완성된 K5셀을 클릭하고 자동 채우기(우측 하단에서 클릭 드래그)를 진행합니다.
결과, 원본 이메일에서 도메인만 추출되었습니다.
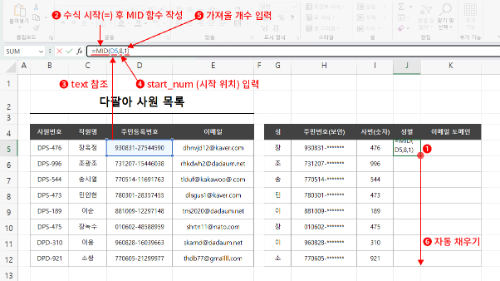
RIGHT 함수 대신 MID 함수를 사용해도 되겠죠. 이건 직접 해 보시길 바랍니다.
힌트, MID 함수의 text와 num_chars 인수는 지금 한 RIGHT 함수의 text와 num_chars 인수와 동일하고 start_num 인수는 @ 다음 위치입니다.
수식만 확인하겠습니다.
주의하실 것을 start_num 인수입니다. "@"부터가 아니라 "@" 다음 문자부터라는 것이 핵심이죠.
MID 함수로는 좀 복잡해 보입니다. RIGHT를 사용하는 것이 좋겠네요.